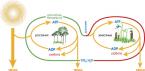
Язык SQL подразделяется на несколько частей, здесь я рассмотрю 2 наиболее важные его части:
- DML – Data Manipulation Language (язык манипулирования данными), который содержит следующие конструкции:
- SELECT – выборка данных
- INSERT – вставка новых данных
- UPDATE – обновление данных
- DELETE – удаление данных
- MERGE – слияние данных
Данный учебник создан по принципу Step by Step, т.е. необходимо читать его последовательно и желательно сразу же выполняя примеры. Но если по ходу у вас возникает потребность узнать о какой-то команде более детально, то используйте конкретный поиск в интернет, например, в библиотеке MSDN.
При написании данного учебника использовалась база данных MS SQL Server версии 2014, для выполнения скриптов я использовал MS SQL Server Management Studio (SSMS).
Кратко о MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) - утилита для Microsoft SQL Server для конфигурирования, управления и администрирования компонентов базы данных. Данная утилита содержит редактор скриптов (который в основном и будет нами использоваться) и графическую программу, которая работает с объектами и настройками сервера. Главным инструментом SQL Server Management Studio является Object Explorer, который позволяет пользователю просматривать, извлекать объекты сервера, а также управлять ими. Данный текст частично позаимствован с википедии.
Для создания нового редактора скрипта используйте кнопку «New Query/Новый запрос»:
Для смены текущей базы данных можно использовать выпадающий список:

Для выполнения определенной команды (или группы команд) выделите ее и нажмите кнопку «Execute/Выполнить» или же клавишу «F5». Если в редакторе в текущий момент находится только одна команда, или же вам необходимо выполнить все команды, то ничего выделять не нужно.

После выполнения скриптов, в особенности создающих объекты (таблицы, столбцы, индексы), чтобы увидеть изменения, используйте обновление из контекстного меню, выделив соответствующую группу (например, Таблицы), саму таблицу или группу Столбцы в ней.

Собственно, это все, что нам необходимо будет знать для выполнения приведенных здесь примеров. Остальное по утилите SSMS несложно изучить самостоятельно.
Немного теории
Реляционная база данных (РБД, или далее в контексте просто БД) представляет из себя совокупность таблиц, связанных между собой. Если говорить грубо, то БД – файл в котором данные хранятся в структурированном виде.СУБД – Система Управления этими Базами Данных, т.е. это комплекс инструментов для работы с конкретным типом БД (MS SQL, Oracle, MySQL, Firebird, …).
Примечание
Т.к. в жизни, в разговорной речи, мы по большей части говорим: «БД Oracle», или даже просто «Oracle», на самом деле подразумевая «СУБД Oracle», то в контексте данного учебника иногда будет употребляться термин БД. Из контекста, я думаю, будет понятно, о чем именно идет речь.
Таблица представляет из себя совокупность столбцов. Столбцы, так же могут называть полями или колонками, все эти слова будут использоваться как синонимы, выражающие одно и тоже.
Таблица – это главный объект РБД, все данные РБД хранятся построчно в столбцах таблицы. Строки, записи – тоже синонимы.
Для каждой таблицы, как и ее столбцов задаются наименования, по которым впоследствии к ним идет обращение.
Наименование объекта (имя таблицы, имя столбца, имя индекса и т.п.) в MS SQL может иметь максимальную длину 128 символов.
Для справки – в БД ORACLE наименования объектов могут иметь максимальную длину 30 символов. Поэтому для конкретной БД нужно вырабатывать свои правила для наименования объектов, чтобы уложиться в лимит по количеству символов.
SQL - язык позволяющий осуществлять запросы в БД посредством СУБД. В конкретной СУБД, язык SQL может иметь специфичную реализацию (свой диалект).
DDL и DML - подмножество языка SQL:
- Язык DDL служит для создания и модификации структуры БД, т.е. для создания/изменения/удаления таблиц и связей.
- Язык DML позволяет осуществлять манипуляции с данными таблиц, т.е. с ее строками. Он позволяет делать выборку данных из таблиц, добавлять новые данные в таблицы, а так же обновлять и удалять существующие данные.
В языке SQL можно использовать 2 вида комментариев (однострочный и многострочный):
Однострочный комментарий
и
/* многострочный комментарий */
Собственно, все для теории этого будет достаточно.
DDL – Data Definition Language (язык описания данных)
Для примера рассмотрим таблицу с данными о сотрудниках, в привычном для человека не являющимся программистом виде:В данном случае столбцы таблицы имеют следующие наименования: Табельный номер, ФИО, Дата рождения, E-mail, Должность, Отдел.
Каждый из этих столбцов можно охарактеризовать по типу содержащемся в нем данных:
- Табельный номер – целое число
- ФИО – строка
- Дата рождения – дата
- E-mail – строка
- Должность – строка
- Отдел – строка
Для начала будет достаточно запомнить только следующие основные типы данных используемые в MS SQL:
| Значение | Обозначение в MS SQL | Описание |
|---|---|---|
| Строка переменной длины | varchar(N) и nvarchar(N) |
При помощи числа N, мы можем указать максимально возможную длину строки для соответствующего столбца. Например, если мы хотим сказать, что значение столбца «ФИО» может содержать максимум 30 символов, то необходимо задать ей тип nvarchar(30). Отличие varchar от nvarchar заключается в том, что varchar позволяет хранить строки в формате ASCII, где один символ занимает 1 байт, а nvarchar хранит строки в формате Unicode, где каждый символ занимает 2 байта. Тип varchar стоит использовать только в том случае, если вы на 100% уверены, что в данном поле не потребуется хранить Unicode символы. Например, varchar можно использовать для хранения адресов электронной почты, т.к. они обычно содержат только ASCII символы. |
| Строка фиксированной длины | char(N) и nchar(N) |
От строки переменной длины данный тип отличается тем, что если длина строка меньше N символов, то она всегда дополняется справа до длины N пробелами и сохраняется в БД в таком виде, т.е. в базе данных она занимает ровно N символов (где один символ занимает 1 байт для char и 2 байта для типа nchar). На моей практике данный тип очень редко находит применение, а если и используется, то он используется в основном в формате char(1), т.е. когда поле определяется одним символом. |
| Целое число | int | Данный тип позволяет нам использовать в столбце только целые числа, как положительные, так и отрицательные. Для справки (сейчас это не так актуально для нас) – диапазон чисел который позволяет тип int от -2 147 483 648 до 2 147 483 647. Обычно это основной тип, который используется для задания идентификаторов. |
| Вещественное или действительное число | float | Если говорить простым языком, то это числа, в которых может присутствовать десятичная точка (запятая). |
| Дата | date | Если в столбце необходимо хранить только Дату, которая состоит из трех составляющих: Числа, Месяца и Года. Например, 15.02.2014 (15 февраля 2014 года). Данный тип можно использовать для столбца «Дата приема», «Дата рождения» и т.п., т.е. в тех случаях, когда нам важно зафиксировать только дату, или, когда составляющая времени нам не важна и ее можно отбросить или если она не известна. |
| Время | time | Данный тип можно использовать, если в столбце необходимо хранить только данные о времени, т.е. Часы, Минуты, Секунды и Миллисекунды. Например, 17:38:31.3231603 Например, ежедневное «Время отправления рейса». |
| Дата и время | datetime | Данный тип позволяет одновременно сохранить и Дату, и Время. Например, 15.02.2014 17:38:31.323 Для примера это может быть дата и время какого-нибудь события. |
| Флаг | bit | Данный тип удобно применять для хранения значений вида «Да»/«Нет», где «Да» будет сохраняться как 1, а «Нет» будет сохраняться как 0. |
Так же значение поля, в том случае если это не запрещено, может быть не указано, для этой цели используется ключевое слово NULL.
Для выполнения примеров создадим тестовую базу под названием Test.
Простую базу данных (без указания дополнительных параметров) можно создать, выполнив следующую команду:
CREATE DATABASE Test
Удалить базу данных можно командой (стоит быть очень осторожным с данной командой):
DROP DATABASE Test
Для того, чтобы переключиться на нашу базу данных, можно выполнить команду:
USE Test
Или же выберите базу данных Test в выпадающем списке в области меню SSMS. При работе мною чаще используется именно этот способ переключения между базами.
Теперь в нашей БД мы можем создать таблицу используя описания в том виде как они есть, используя пробелы и символы кириллицы:
CREATE TABLE [Сотрудники]([Табельный номер] int,
[ФИО] nvarchar(30),
[Дата рождения] date,
nvarchar(30),
[Должность] nvarchar(30),
[Отдел] nvarchar(30))
В данном случае нам придется заключать имена в квадратные скобки […].
Но в базе данных для большего удобства все наименования объектов лучше задавать на латинице и не использовать в именах пробелы. В MS SQL обычно в данном случае каждое слово начинается с прописной буквы, например, для поля «Табельный номер», мы могли бы задать имя PersonnelNumber. Так же в имени можно использовать цифры, например, PhoneNumber1.
На заметку
В некоторых СУБД более предпочтительным может быть следующий формат наименований «PHONE_NUMBER», например, такой формат часто используется в БД ORACLE. Естественно при задании имя поля желательно чтобы оно не совпадало с ключевыми словами используемые в СУБД.
По этой причине можете забыть о синтаксисе с квадратными скобками и удалить таблицу [Сотрудники]:
DROP TABLE [Сотрудники]
Например, таблицу с сотрудниками можно назвать «Employees», а ее полям можно задать следующие наименования:
- ID – Табельный номер (Идентификатор сотрудника)
- Name – ФИО
- Birthday – Дата рождения
- Email – E-mail
- Position – Должность
- Department – Отдел
Теперь создадим нашу таблицу:
CREATE TABLE Employees(ID int,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30))
Для того, чтобы задать обязательные для заполнения столбцы, можно использовать опцию NOT NULL.
Для уже существующей таблицы поля можно переопределить при помощи следующих команд:
Обновление поля ID ALTER TABLE Employees ALTER COLUMN ID int NOT NULL -- обновление поля Name ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NOT NULL
На заметку
Общая концепция языка SQL для большинства СУБД остается одинаковой (по крайней мере, об этом я могу судить по тем СУБД, с которыми мне довелось поработать). Отличие DDL в разных СУБД в основном заключаются в типах данных (здесь могут отличаться не только их наименования, но и детали их реализации), так же может немного отличаться и сама специфика реализации языка SQL (т.е. суть команд одна и та же, но могут быть небольшие различия в диалекте, увы, но одного стандарта нет). Владея основами SQL вы легко сможете перейти с одной СУБД на другую, т.к. вам в данном случае нужно будет только разобраться в деталях реализации команд в новой СУБД, т.е. в большинстве случаев достаточно будет просто провести аналогию.Создание таблицы CREATE TABLE Employees(ID int, -- в ORACLE тип int - это эквивалент(обертка) для number(38) Name nvarchar2(30), -- nvarchar2 в ORACLE эквивалентен nvarchar в MS SQL Birthday date, Email nvarchar2(30), Position nvarchar2(30), Department nvarchar2(30)); -- обновление полей ID и Name (здесь вместо ALTER COLUMN используется MODIFY(…)) ALTER TABLE Employees MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- добавление PK (в данном случае конструкция выглядит как и в MS SQL, она будет показана ниже) ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);
Для ORACLE есть отличия в плане реализации типа varchar2, его кодировка зависит настроек БД и текст может сохраняться, например, в кодировке UTF-8. Помимо этого длину поля в ORACLE можно задать как в байтах, так и в символах, для этого используются дополнительные опции BYTE и CHAR, которые указываются после длины поля, например:NAME varchar2(30 BYTE) -- вместимость поля будет равна 30 байтам NAME varchar2(30 CHAR) -- вместимость поля будет равна 30 символов
Какая опция будет использоваться по умолчанию BYTE или CHAR, в случае простого указания в ORACLE типа varchar2(30), зависит от настроек БД, так же она иногда может задаваться в настройках IDE. В общем порой можно легко запутаться, поэтому в случае ORACLE, если используется тип varchar2 (а это здесь порой оправдано, например, при использовании кодировки UTF-8) я предпочитаю явно прописывать CHAR (т.к. обычно длину строки удобнее считать именно в символах).
Но в данном случае если в таблице уже есть какие-нибудь данные, то для успешного выполнения команд необходимо, чтобы во всех строках таблицы поля ID и Name были обязательно заполнены. Продемонстрируем это на примере, вставим в таблицу данные в поля ID, Position и Department, это можно сделать следующим скриптом:
INSERT Employees(ID,Position,Department) VALUES
(1000,N"Директор",N"Администрация"),
(1001,N"Программист",N"ИТ"),
(1002,N"Бухгалтер",N"Бухгалтерия"),
(1003,N"Старший программист",N"ИТ")
В данном случае, команда INSERT также выдаст ошибку, т.к. при вставке мы не указали значения обязательного поля Name.
В случае, если бы у нас в первоначальной таблице уже имелись эти данные, то команда «ALTER TABLE Employees ALTER COLUMN ID int NOT NULL» выполнилась бы успешно, а команда «ALTER TABLE Employees ALTER COLUMN Name int NOT NULL» выдала сообщение об ошибке, что в поле Name имеются NULL (не указанные) значения.
Добавим значения для полю Name и снова зальем данные:
Так же опцию NOT NULL можно использовать непосредственно при создании новой таблицы, т.е. в контексте команды CREATE TABLE.
Сначала удалим таблицу при помощи команды:
DROP TABLE Employees
Теперь создадим таблицу с обязательными для заполнения столбцами ID и Name:
CREATE TABLE Employees(ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30))
Можно также после имени столбца написать NULL, что будет означать, что в нем будут допустимы NULL-значения (не указанные), но этого делать не обязательно, так как данная характеристика подразумевается по умолчанию.
Если требуется наоборот сделать существующий столбец необязательным для заполнения, то используем следующий синтаксис команды:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NULL
Или просто:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30)
Так же данной командой мы можем изменить тип поля на другой совместимый тип, или же изменить его длину. Для примера давайте расширим поле Name до 50 символов:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(50)
Первичный ключ
При создании таблицы желательно, чтобы она имела уникальный столбец или же совокупность столбцов, которая уникальна для каждой ее строки – по данному уникальному значению можно однозначно идентифицировать запись. Такое значение называется первичным ключом таблицы. Для нашей таблицы Employees таким уникальным значением может быть столбец ID (который содержит «Табельный номер сотрудника» - пускай в нашем случае данное значение уникально для каждого сотрудника и не может повторяться).Создать первичный ключ к уже существующей таблице можно при помощи команды:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
Где «PK_Employees» это имя ограничения, отвечающего за первичный ключ. Обычно для наименования первичного ключа используется префикс «PK_» после которого идет имя таблицы.
Если первичный ключ состоит из нескольких полей, то эти поля необходимо перечислить в скобках через запятую:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY(поле1,поле2,…)
Стоит отметить, что в MS SQL все поля, которые входят в первичный ключ, должны иметь характеристику NOT NULL.
Так же первичный ключ можно определить непосредственно при создании таблицы, т.е. в контексте команды CREATE TABLE. Удалим таблицу:
DROP TABLE Employees
А затем создадим ее, используя следующий синтаксис:
CREATE TABLE Employees(ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30),
CONSTRAINT PK_Employees PRIMARY KEY(ID) -- описываем PK после всех полей, как ограничение)
После создания зальем в таблицу данные:
INSERT Employees(ID,Position,Department,Name) VALUES
(1000,N"Директор",N"Администрация",N"Иванов И.И."),
(1001,N"Программист",N"ИТ",N"Петров П.П."),
(1002,N"Бухгалтер",N"Бухгалтерия",N"Сидоров С.С."),
(1003,N"Старший программист",N"ИТ",N"Андреев А.А.")
Если первичный ключ в таблице состоит только из значений одного столбца, то можно использовать следующий синтаксис:
CREATE TABLE Employees(ID int NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, -- указываем как характеристику поля
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30))
На самом деле имя ограничения можно и не задавать, в этом случае ему будет присвоено системное имя (наподобие «PK__Employee__3214EC278DA42077»):
CREATE TABLE Employees(ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30),
PRIMARY KEY(ID))
Или:
CREATE TABLE Employees(ID int NOT NULL PRIMARY KEY,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30))
Но я бы рекомендовал для постоянных таблиц всегда явно задавать имя ограничения, т.к. по явно заданному и понятному имени с ним впоследствии будет легче проводить манипуляции, например, можно произвести его удаление:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
Но такой краткий синтаксис, без указания имен ограничений, удобно применять при создании временных таблиц БД (имя временной таблицы начинается с # или ##), которые после использования будут удалены.
Подытожим
На данный момент мы рассмотрели следующие команды:- CREATE TABLE имя_таблицы (перечисление полей и их типов, ограничений) – служит для создания новой таблицы в текущей БД;
- DROP TABLE имя_таблицы – служит для удаления таблицы из текущей БД;
- ALTER TABLE имя_таблицы ALTER COLUMN имя_столбца … – служит для обновления типа столбца или для изменения его настроек (например для задания характеристики NULL или NOT NULL);
- ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY (поле1, поле2,…) – добавление первичного ключа к уже существующей таблице;
- ALTER TABLE имя_таблицы DROP CONSTRAINT имя_ограничения – удаление ограничения из таблицы.
Немного про временные таблицы
Вырезка из MSDN. В MS SQL Server существует два вида временных таблиц: локальные (#) и глобальные (##). Локальные временные таблицы видны только их создателям до завершения сеанса соединения с экземпляром SQL Server, как только они впервые созданы. Локальные временные таблицы автоматически удаляются после отключения пользователя от экземпляра SQL Server. Глобальные временные таблицы видны всем пользователям в течение любых сеансов соединения после создания этих таблиц и удаляются, когда все пользователи, ссылающиеся на эти таблицы, отключаются от экземпляра SQL Server.
Временные таблицы создаются в системной базе tempdb, т.е. создавая их мы не засоряем основную базу, в остальном же временные таблицы полностью идентичны обычным таблицам, их так же можно удалить при помощи команды DROP TABLE. Чаще используются локальные (#) временные таблицы.
Для создания временной таблицы можно использовать команду CREATE TABLE:
CREATE TABLE #Temp(ID int,
Name nvarchar(30))
Так как временная таблица в MS SQL аналогична обычной таблице, ее соответственно так же можно удалить самому командой DROP TABLE:
DROP TABLE #Temp
Так же временную таблицу (как собственно и обычную таблицу) можно создать и сразу заполнить данными возвращаемые запросом используя синтаксис SELECT … INTO:
SELECT ID,Name
INTO #Temp
FROM Employees
На заметку
В разных СУБД реализация временных таблиц может отличаться. Например, в СУБД ORACLE и Firebird структура временных таблиц должна быть определена заранее командой CREATE GLOBAL TEMPORARY TABLE с указанием специфики хранения в ней данных, дальше уже пользователь видит ее среди основных таблиц и работает с ней как с обычной таблицей.
Нормализация БД – дробление на подтаблицы (справочники) и определение связей
Наша текущая таблица Employees имеет недостаток в том, что в полях Position и Department пользователь может ввести любой текст, что в первую очередь чревато ошибками, так как он у одного сотрудника может указать в качестве отдела просто «ИТ», а у второго сотрудника, например, ввести «ИТ-отдел», у третьего «IT». В итоге будет непонятно, что имел ввиду пользователь, т.е. являются ли данные сотрудники работниками одного отдела, или же пользователь описался и это 3 разных отдела? А тем более, в этом случае, мы не сможем правильно сгруппировать данные для какого-то отчета, где, может требоваться показать количество сотрудников в разрезе каждого отдела.Второй недостаток заключается в объеме хранения данной информации и ее дублированием, т.е. для каждого сотрудника указывается полное наименование отдела, что требует в БД места для хранения каждого символа из названия отдела.
Третий недостаток – сложность обновления данных полей, в случае если изменится название какой-то должности, например, если потребуется переименовать должность «Программист», на «Младший программист». В данном случае нам придется вносить изменения в каждую строчку таблицы, у которой Должность равняется «Программист».
Чтобы избежать данных недостатков и применяется, так называемая, нормализация базы данных – дробление ее на подтаблицы, таблицы справочники. Не обязательно лезть в дебри теории и изучать что из себя представляют нормальные формы, достаточно понимать суть нормализации.
Давайте создадим 2 таблицы справочники «Должности» и «Отделы», первую назовем Positions, а вторую соответственно Departments:
CREATE TABLE Positions(ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY,
Name nvarchar(30) NOT NULL)
CREATE TABLE Departments(ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY,
Name nvarchar(30) NOT NULL)
Заметим, что здесь мы использовали новую опцию IDENTITY, которая говорит о том, что данные в столбце ID будут нумероваться автоматически, начиная с 1, с шагом 1, т.е. при добавлении новых записей им последовательно будут присваиваться значения 1, 2, 3, и т.д. Такие поля обычно называют автоинкрементными. В таблице может быть определено только одно поле со свойством IDENTITY и обычно, но необязательно, такое поле является первичным ключом для данной таблицы.
На заметку
В разных СУБД реализация полей со счетчиком может делаться по своему. В MySQL, например, такое поле определяется при помощи опции AUTO_INCREMENT. В ORACLE и Firebird раньше данную функциональность можно было съэмулировать при помощи использования последовательностей (SEQUENCE). Но насколько я знаю в ORACLE сейчас добавили опцию GENERATED AS IDENTITY.
Давайте заполним эти таблицы автоматически, на основании текущих данных записанных в полях Position и Department таблицы Employees:
Заполняем поле Name таблицы Positions, уникальными значениями из поля Position таблицы Employees
INSERT Positions(Name)
SELECT DISTINCT Position
FROM Employees
WHERE Position IS NOT NULL -- отбрасываем записи у которых позиция не указана
То же самое проделаем для таблицы Departments:
INSERT Departments(Name)
SELECT DISTINCT Department
FROM Employees
WHERE Department IS NOT NULL
Если теперь мы откроем таблицы Positions и Departments, то увидим пронумерованный набор значений по полю ID:
SELECT * FROM Positions
SELECT * FROM Departments
Данные таблицы теперь и будут играть роль справочников для задания должностей и отделов. Теперь мы будем ссылаться на идентификаторы должностей и отделов. В первую очередь создадим новые поля в таблице Employees для хранения данных идентификаторов:
Добавляем поле для ID должности
ALTER TABLE Employees ADD PositionID int
-- добавляем поле для ID отдела
ALTER TABLE Employees ADD DepartmentID int
Тип ссылочных полей должен быть каким же, как и в справочниках, в данном случае это int.
Так же добавить в таблицу сразу несколько полей можно одной командой, перечислив поля через запятую:
ALTER TABLE Employees ADD PositionID int, DepartmentID int
Теперь пропишем ссылки (ссылочные ограничения - FOREIGN KEY) для этих полей, для того чтобы пользователь не имел возможности записать в данные поля, значения, отсутствующие среди значений ID находящихся в справочниках.
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_PositionID
FOREIGN KEY(PositionID) REFERENCES Positions(ID)
И то же самое сделаем для второго поля:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_DepartmentID
FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
Теперь пользователь в данные поля сможет занести только значения ID из соответствующего справочника. Соответственно, чтобы использовать новый отдел или должность, он первым делом должен будет добавить новую запись в соответствующий справочник. Т.к. должности и отделы теперь хранятся в справочниках в одном единственном экземпляре, то чтобы изменить название, достаточно изменить его только в справочнике.
Имя ссылочного ограничения, обычно является составным, оно состоит из префикса «FK_», затем идет имя таблицы и после знака подчеркивания идет имя поля, которое ссылается на идентификатор таблицы-справочника.
Идентификатор (ID) обычно является внутренним значением, которое используется только для связей и какое значение там хранится, в большинстве случаев абсолютно безразлично, поэтому не нужно пытаться избавиться от дырок в последовательности чисел, которые возникают по ходу работы с таблицей, например, после удаления записей из справочника.
ALTER TABLE таблица ADD CONSTRAINT имя_ограничения
FOREIGN KEY(поле1,поле2,…) REFERENCES таблица_справочник(поле1,поле2,…)
В данном случае в таблице «таблица_справочник» первичный ключ представлен комбинацией из нескольких полей (поле1, поле2,…).
Собственно, теперь обновим поля PositionID и DepartmentID значениями ID из справочников. Воспользуемся для этой цели DML командой UPDATE:
UPDATE e
SET
PositionID=(SELECT ID FROM Positions WHERE Name=e.Position),
DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department)
FROM Employees e
Посмотрим, что получилось, выполнив запрос:
SELECT * FROM Employees
Всё, поля PositionID и DepartmentID заполнены соответствующие должностям и отделам идентификаторами надобности в полях Position и Department в таблице Employees теперь нет, можно удалить эти поля:
ALTER TABLE Employees DROP COLUMN Position,Department
Теперь таблица у нас приобрела следующий вид:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | NULL | NULL | 2 | 1 |
| 1001 | Петров П.П. | NULL | NULL | 3 | 3 |
| 1002 | Сидоров С.С. | NULL | NULL | 1 | 2 |
| 1003 | Андреев А.А. | NULL | NULL | 4 | 3 |
Т.е. мы в итоге избавились от хранения избыточной информации. Теперь, по номерам должности и отдела можем однозначно определить их названия, используя значения в таблицах-справочниках:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName
FROM Employees e
LEFT JOIN Departments d ON d.ID=e.DepartmentID
LEFT JOIN Positions p ON p.ID=e.PositionID
В инспекторе объектов мы можем увидеть все объекты, созданные для в данной таблицы. Отсюда же можно производить разные манипуляции с данными объектами – например, переименовывать или удалять объекты.

Так же стоит отметить, что таблица может ссылаться сама на себя, т.е. можно создать рекурсивную ссылку. Для примера добавим в нашу таблицу с сотрудниками еще одно поле ManagerID, которое будет указывать на сотрудника, которому подчиняется данный сотрудник. Создадим поле:
ALTER TABLE Employees ADD ManagerID int
В данном поле допустимо значение NULL, поле будет пустым, если, например, над сотрудником нет вышестоящих.
Теперь создадим FOREIGN KEY на таблицу Employees:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID
FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
Давайте, теперь создадим диаграмму и посмотрим, как выглядят на ней связи между нашими таблицами:


В результате мы должны увидеть следующую картину (таблица Employees связана с таблицами Positions и Depertments, а так же ссылается сама на себя):

Напоследок стоит сказать, что ссылочные ключи могут включать дополнительные опции ON DELETE CASCADE и ON UPDATE CASCADE, которые говорят о том, как вести себя при удалении или обновлении записи, на которую есть ссылки в таблице-справочнике. Если эти опции не указаны, то мы не можем изменить ID в таблице справочнике у той записи, на которую есть ссылки из другой таблицы, так же мы не сможем удалить такую запись из справочника, пока не удалим все строки, ссылающиеся на эту запись или, же обновим в этих строках ссылки на другое значение.
Для примера пересоздадим таблицу с указанием опции ON DELETE CASCADE для FK_Employees_DepartmentID:
DROP TABLE Employees
CREATE TABLE Employees(ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
ON DELETE CASCADE,
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID))
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES
(1000,N"Иванов И.И.","19550219",2,1,NULL),
(1001,N"Петров П.П.","19831203",3,3,1003),
(1002,N"Сидоров С.С.","19760607",1,2,1000),
(1003,N"Андреев А.А.","19820417",4,3,1000)
Удалим отдел с идентификатором 3 из таблицы Departments:
DELETE Departments WHERE ID=3
Посмотрим на данные таблицы Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Сидоров С.С. | 1976-06-07 | NULL | 1 | 2 | 1000 |
Как видим, данные по отделу 3 из таблицы Employees так же удалились.
Опция ON UPDATE CASCADE ведет себя аналогично, но действует она при обновлении значения ID в справочнике. Например, если мы поменяем ID должности в справочнике должностей, то в этом случае будет производиться обновление DepartmentID в таблице Employees на новое значение ID которое мы задали в справочнике. Но в данном случае это продемонстрировать просто не получится, т.к. у колонки ID в таблице Departments стоит опция IDENTITY, которая не позволит нам выполнить следующий запрос (сменить идентификатор отдела 3 на 30):
UPDATE Departments
SET
ID=30
WHERE ID=3
Главное понять суть этих 2-х опций ON DELETE CASCADE и ON UPDATE CASCADE. Я применяю эти опции очень в редких случаях и рекомендую хорошо подумать, прежде чем указывать их в ссылочном ограничении, т.к. при нечаянном удалении записи из таблицы справочника это может привести к большим проблемам и создать цепную реакцию.
Восстановим отдел 3:
Даем разрешение на добавление/изменение IDENTITY значения
SET IDENTITY_INSERT Departments ON
INSERT Departments(ID,Name) VALUES(3,N"ИТ")
-- запрещаем добавление/изменение IDENTITY значения
SET IDENTITY_INSERT Departments OFF
Полностью очистим таблицу Employees при помощи команды TRUNCATE TABLE:
TRUNCATE TABLE Employees
И снова перезальем в нее данные используя предыдущую команду INSERT:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N"Иванов И.И.","19550219",2,1,NULL), (1001,N"Петров П.П.","19831203",3,3,1003), (1002,N"Сидоров С.С.","19760607",1,2,1000), (1003,N"Андреев А.А.","19820417",4,3,1000)
Подытожим
На данным момент к нашим знаниям добавилось еще несколько команд DDL:- Добавление свойства IDENTITY к полю – позволяет сделать это поле автоматически заполняемым (полем-счетчиком) для таблицы;
- ALTER TABLE имя_таблицы ADD перечень_полей_с_характеристиками – позволяет добавить новые поля в таблицу;
- ALTER TABLE имя_таблицы DROP COLUMN перечень_полей – позволяет удалить поля из таблицы;
- ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения FOREIGN KEY (поля) REFERENCES таблица_справочник(поля) – позволяет определить связь между таблицей и таблицей справочником.
Прочие ограничения – UNIQUE, DEFAULT, CHECK
При помощи ограничения UNIQUE можно сказать что значения для каждой строки в данном поле или в наборе полей должно быть уникальным. В случае таблицы Employees, такое ограничение мы можем наложить на поле Email. Только предварительно заполним Email значениями, если они еще не определены:UPDATE Employees SET Email="[email protected]" WHERE ID=1000
UPDATE Employees SET Email="[email protected]" WHERE ID=1001
UPDATE Employees SET Email="[email protected]" WHERE ID=1002
UPDATE Employees SET Email="[email protected]" WHERE ID=1003
А теперь можно наложить на это поле ограничение-уникальности:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Теперь пользователь не сможет внести один и тот же E-Mail у нескольких сотрудников.
Ограничение уникальности обычно именуется следующим образом – сначала идет префикс «UQ_», далее название таблицы и после знака подчеркивания идет имя поля, на которое накладывается данное ограничение.
Соответственно если уникальной в разрезе строк таблицы должна быть комбинация полей, то перечисляем их через запятую:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения UNIQUE(поле1,поле2,…)
При помощи добавления к полю ограничения DEFAULT мы можем задать значение по умолчанию, которое будет подставляться в случае, если при вставке новой записи данное поле не будет перечислено в списке полей команды INSERT. Данное ограничение можно задать непосредственно при создании таблицы.
Давайте добавим в таблицу Employees новое поле «Дата приема» и назовем его HireDate и скажем что значение по умолчанию у данного поля будет текущая дата:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
Или если столбец HireDate уже существует, то можно использовать следующий синтаксис:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
Здесь я не указал имя ограничения, т.к. в случае DEFAULT у меня сложилось мнение, что это не столь критично. Но если делать по-хорошему, то, думаю, не нужно лениться и стоит задать нормальное имя. Делается это следующим образом:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
Та как данного столбца раньше не было, то при его добавлении в каждую запись в поле HireDate будет вставлено текущее значение даты.
При добавлении новой записи, текущая дата так же будет вставлена автоматом, конечно если мы ее явно не зададим, т.е. не укажем в списке столбцов. Покажем это на примере, не указав поле HireDate в перечне добавляемых значений:
INSERT Employees(ID,Name,Email)VALUES(1004,N"Сергеев С.С.","[email protected]")
Посмотрим, что получилось:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | [email protected] | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Петров П.П. | 1983-12-03 | [email protected] | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Сидоров С.С. | 1976-06-07 | [email protected] | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Андреев А.А. | 1982-04-17 | [email protected] | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Сергеев С.С. | NULL | [email protected] | NULL | NULL | NULL | 2015-04-08 |
Проверочное ограничение CHECK используется в том случае, когда необходимо осуществить проверку вставляемых в поле значений. Например, наложим данное ограничение на поле табельный номер, которое у нас является идентификатором сотрудника (ID). При помощи данного ограничения скажем, что табельные номера должны иметь значение от 1000 до 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
Ограничение обычно именуется так же, сначала идет префикс «CK_», затем имя таблицы и имя поля, на которое наложено это ограничение.
Попробуем вставить недопустимую запись для проверки, что ограничение работает (мы должны получить соответствующую ошибку):
INSERT Employees(ID,Email) VALUES(2000,"[email protected]")
А теперь изменим вставляемое значение на 1500 и убедимся, что запись вставится:
INSERT Employees(ID,Email) VALUES(1500,"[email protected]")
Можно так же создать ограничения UNIQUE и CHECK без указания имени:
ALTER TABLE Employees ADD UNIQUE(Email)
ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Но это не очень хорошая практика и лучше задавать имя ограничения в явном виде, т.к. чтобы разобраться потом, что будет сложнее, нужно будет открывать объект и смотреть, за что он отвечает.

При хорошем наименовании много информации об ограничении можно узнать непосредственно по его имени.
И, соответственно, все эти ограничения можно создать сразу же при создании таблицы, если ее еще нет. Удалим таблицу:
DROP TABLE Employees
И пересоздадим ее со всеми созданными ограничениями одной командой CREATE TABLE:
CREATE TABLE Employees(ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL DEFAULT SYSDATETIME(), -- для DEFAULT я сделаю исключение
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT UQ_Employees_Email UNIQUE (Email),
CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999))
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES (1000,N"Иванов И.И.","19550219","[email protected]",2,1), (1001,N"Петров П.П.","19831203","[email protected]",3,3), (1002,N"Сидоров С.С.","19760607","[email protected]",1,2), (1003,N"Андреев А.А.","19820417","[email protected]",4,3)
Немного про индексы, создаваемые при создании ограничений PRIMARY KEY и UNIQUE
Как можно увидеть на скриншоте выше, при создании ограничений PRIMARY KEY и UNIQUE автоматически создались индексы с такими же названиями (PK_Employees и UQ_Employees_Email). По умолчанию индекс для первичного ключа создается как CLUSTERED, а для всех остальных индексов как NONCLUSTERED. Стоит сказать, что понятие кластерного индекса есть не во всех СУБД. Таблица может иметь только один кластерный (CLUSTERED) индекс. CLUSTERED – означает, что записи таблицы будут сортироваться по этому индексу, так же можно сказать, что этот индекс имеет непосредственный доступ ко всем данным таблицы. Это так сказать главный индекс таблицы. Если сказать еще грубее, то это индекс, прикрученный к таблице. Кластерный индекс – это очень мощное средство, которое может помочь при оптимизации запросов, пока просто запомним это. Если мы хотим сказать, чтобы кластерный индекс использовался не в первичном ключе, а для другого индекса, то при создании первичного ключа мы должны указать опцию NONCLUSTERED:ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения
PRIMARY KEY NONCLUSTERED(поле1,поле2,…)
Для примера сделаем индекс ограничения PK_Employees некластерным, а индекс ограничения UQ_Employees_Email кластерным. Первым делом удалим данные ограничения:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
А теперь создадим их с опциями CLUSTERED и NONCLUSTERED:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID)
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Теперь, выполнив выборку из таблицы Employees, мы увидим, что записи отсортировались по кластерному индексу UQ_Employees_Email:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
|---|---|---|---|---|---|---|
| 1003 | Андреев А.А. | 1982-04-17 | [email protected] | 4 | 3 | 2015-04-08 |
| 1000 | Иванов И.И. | 1955-02-19 | [email protected] | 2 | 1 | 2015-04-08 |
| 1001 | Петров П.П. | 1983-12-03 | [email protected] | 3 | 3 | 2015-04-08 |
| 1002 | Сидоров С.С. | 1976-06-07 | [email protected] | 1 | 2 | 2015-04-08 |
До этого, когда кластерным индексом был индекс PK_Employees, записи по умолчанию сортировались по полю ID.
Но в данном случае это всего лишь пример, который показывает суть кластерного индекса, т.к. скорее всего к таблице Employees будут делаться запросы по полю ID и в каких-то случаях, возможно, она сама будет выступать в роли справочника.
Для справочников обычно целесообразно, чтобы кластерный индекс был построен по первичному ключу, т.к. в запросах мы часто ссылаемся на идентификатор справочника для получения, например, наименования (Должности, Отдела). Здесь вспомним, о чем я писал выше, что кластерный индекс имеет прямой доступ к строкам таблицы, а отсюда следует, что мы можем получить значение любого столбца без дополнительных накладных расходов.
Кластерный индекс выгодно применять к полям, по которым выборка идет наиболее часто.
Иногда в таблицах создают ключ по суррогатному полю, вот в этом случае бывает полезно сохранить опцию CLUSTERED индекс для более подходящего индекса и указать опцию NONCLUSTERED при создании суррогатного первичного ключа.
Подытожим
На данном этапе мы познакомились со всеми видами ограничений, в их самом простом виде, которые создаются командой вида «ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения …»:- PRIMARY KEY – первичный ключ;
- FOREIGN KEY – настройка связей и контроль ссылочной целостности данных;
- UNIQUE – позволяет создать уникальность;
- CHECK – позволяет осуществлять корректность введенных данных;
- DEFAULT – позволяет задать значение по умолчанию;
- Так же стоит отметить, что все ограничения можно удалить, используя команду «ALTER TABLE имя_таблицы DROP CONSTRAINT имя_ограничения».
Создание самостоятельных индексов
Под самостоятельностью здесь имеются в виду индексы, которые создаются не для ограничения PRIMARY KEY или UNIQUE.Индексы по полю или полям можно создавать следующей командой:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Так же здесь можно указать опции CLUSTERED, NONCLUSTERED, UNIQUE, а так же можно указать направление сортировки каждого отдельного поля ASC (по умолчанию) или DESC:
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
При создании некластерного индекса опцию NONCLUSTERED можно отпустить, т.к. она подразумевается по умолчанию, здесь она показана просто, чтобы указать позицию опции CLUSTERED или NONCLUSTERED в команде.
Удалить индекс можно следующей командой:
DROP INDEX IDX_Employees_Name ON Employees
Простые индексы так же, как и ограничения, можно создать в контексте команды CREATE TABLE.
Для примера снова удалим таблицу:
DROP TABLE Employees
И пересоздадим ее со всеми созданными ограничениями и индексами одной командой CREATE TABLE:
CREATE TABLE Employees(ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(),
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID),
CONSTRAINT UQ_Employees_Email UNIQUE(Email),
CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999),
INDEX IDX_Employees_Name(Name))
Напоследок вставим в таблицу наших сотрудников:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES
(1000,N"Иванов И.И.","19550219","[email protected]",2,1,NULL),
(1001,N"Петров П.П.","19831203","[email protected]",3,3,1003),
(1002,N"Сидоров С.С.","19760607","[email protected]",1,2,1000),
(1003,N"Андреев А.А.","19820417","[email protected]",4,3,1000)
Дополнительно стоит отметить, что в некластерный индекс можно включать значения при помощи указания их в INCLUDE. Т.е. в данном случае INCLUDE-индекс чем-то будет напоминать кластерный индекс, только теперь не индекс прикручен к таблице, а необходимые значения прикручены к индексу. Соответственно, такие индексы могут очень повысить производительность запросов на выборку (SELECT), если все перечисленные поля имеются в индексе, то возможно обращений к таблице вообще не понадобится. Но это естественно повышает размер индекса, т.к. значения перечисленных полей дублируются в индексе.
Вырезка из MSDN. Общий синтаксис команды для создания индексовCREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON
Подытожим
Индексы могут повысить скорость выборки данных (SELECT), но индексы уменьшают скорость модификации данных таблицы, т.к. после каждой модификации системе будет необходимо перестроить все индексы для конкретной таблицы.Желательно в каждом случае найти оптимальное решение, золотую середину, чтобы и производительность выборки, так и модификации данных была на должном уровне. Стратегия по созданию индексов и их количества может зависеть от многих факторов, например, насколько часто изменяются данные в таблице.
Заключение по DDL
Как можно увидеть, язык DDL не так сложен, как может показаться на первый взгляд. Здесь я смог показать практически все его основные конструкции, оперируя всего тремя таблицами.Главное - понять суть, а остальное дело практики.
Удачи вам в освоении этого замечательного языка под названием SQL.
Надо “ SELECT * WHERE a=b FROM c ” или “ SELECT WHERE a=b FROM c ON * ” ?
Если вы похожи на меня, то согласитесь: SQL - это одна из тех штук, которые на первый взгляд кажутся легкими (читается как будто по-английски!), но почему-то приходится гуглить каждый простой запрос, чтобы найти правильный синтаксис.
А потом начинаются джойны, агрегирование, подзапросы, и получается совсем белиберда. Вроде такой:
SELECT members.firstname || " " || members.lastname AS "Full Name" FROM borrowings INNER JOIN members ON members.memberid=borrowings.memberid INNER JOIN books ON books.bookid=borrowings.bookid WHERE borrowings.bookid IN (SELECT bookid FROM books WHERE stock>(SELECT avg(stock) FROM books)) GROUP BY members.firstname, members.lastname;
Буэ! Такое спугнет любого новичка, или даже разработчика среднего уровня, если он видит SQL впервые. Но не все так плохо.
Легко запомнить то, что интуитивно понятно, и с помощью этого руководства я надеюсь снизить порог входа в SQL для новичков, а уже опытным предложить по-новому взглянуть на SQL.
Не смотря на то, что синтаксис SQL почти не отличается в разных базах данных, в этой статье для запросов используется PostgreSQL. Некоторые примеры будут работать в MySQL и других базах.
1. Три волшебных слова
В SQL много ключевых слов, но SELECT , FROM и WHERE присутствуют практически в каждом запросе. Чуть позже вы поймете, что эти три слова представляют собой самые фундаментальные аспекты построения запросов к базе, а другие, более сложные запросы, являются всего лишь надстройками над ними.
2. Наша база
Давайте взглянем на базу данных, которую мы будем использовать в качестве примера в этой статье:


У нас есть книжная библиотека и люди. Также есть специальная таблица для учета выданных книг.
- В таблице "books" хранится информация о заголовке, авторе, дате публикации и наличии книги. Все просто.
- В таблице “members” - имена и фамилии всех записавшихся в библиотеку людей.
- В таблице “borrowings” хранится информация о взятых из библиотеки книгах. Колонка bookid относится к идентификатору взятой книги в таблице “books”, а колонка memberid относится к соответствующему человеку из таблицы “members”. У нас также есть дата выдачи и дата, когда книгу нужно вернуть.
3. Простой запрос
Давайте начнем с простого запроса: нам нужны имена и идентификаторы (id) всех книг, написанных автором “Dan Brown”
Запрос будет таким:
SELECT bookid AS "id", title FROM books WHERE author="Dan Brown";
А результат таким:
| id | title |
|---|---|
| 2 | The Lost Symbol |
| 4 | Inferno |
Довольно просто. Давайте разберем запрос чтобы понять, что происходит.
3.1 FROM - откуда берем данные
Сейчас это может показаться очевидным, но FROM будет очень важен позже, когда мы перейдем к соединениям и подзапросам.
FROM указывает на таблицу, по которой нужно делать запрос. Это может быть уже существующая таблица (как в примере выше), или таблица, создаваемая на лету через соединения или подзапросы.
3.2 WHERE - какие данные показываем
WHERE просто-напросто ведет себя как фильтр строк , которые мы хотим вывести. В нашем случае мы хотим видеть только те строки, где значение в колонке author - это “Dan Brown”.
3.3 SELECT - как показываем данные
Теперь, когда у нас есть все нужные нам колонки из нужной нам таблицы, нужно решить, как именно показывать эти данные. В нашем случае нужны только названия и идентификаторы книг, так что именно это мы и выберем с помощью SELECT . Заодно можно переименовать колонку используя AS .
Весь запрос можно визуализировать с помощью простой диаграммы:

4. Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
SELECT books.title AS "Title", borrowings.returndate AS "Return Date" FROM borrowings JOIN books ON borrowings.bookid=books.bookid WHERE books.author="Dan Brown";
Результат:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции FROM . Это означает, что мы запрашиваем данные из другой таблицы . Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице , которая создалась соединением этих двух таблиц.
borrowings JOIN books ON borrowings.bookid=books.bookid - это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц "books" и "borrowings", в которых значения bookid совпадают. Результатом такого слияния будет:

А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 - откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
borrowings JOIN books ON borrowings.bookid=books.bookid JOIN members ON members.memberid=borrowings.memberid
Результат соединения можно увидеть по ссылке .
Шаг 2 - какие данные показываем? Нас интересуют только те данные, где автор книги - “Dan Brown”
WHERE books.author="Dan Brown"
Шаг 3 - как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
SELECT members.firstname AS "First Name", members.lastname AS "Last Name"
Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
SELECT members.firstname AS "First Name", members.lastname AS "Last Name" FROM borrowings JOIN books ON borrowings.bookid=books.bookid JOIN members ON members.memberid=borrowings.memberid WHERE books.author="Dan Brown";
Что даст нам:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
5. Агрегирование
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну . При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
SELECT members.firstname AS "First Name", members.lastname AS "Last Name", count(*) AS "Number of books borrowed" FROM borrowings JOIN books ON borrowings.bookid=books.bookid JOIN members ON members.memberid=borrowings.memberid WHERE books.author="Dan Brown" GROUP BY members.firstname, members.lastname;
Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением GROUP BY . Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в GROUP BY . В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с count , которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.
Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в GROUP BY , или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их SELECT "ом, то непонятно, какие из возможных значений нужно брать.
В примере выше функция count обрабатывала все строки (так как мы считали количество строк). Другие функции вроде sum или max обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
SELECT author, sum(stock) FROM books GROUP BY author;
Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция sum обрабатывает только колонку stock и считает сумму всех значений в каждой группе.
6. Подзапросы

Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
6.1 Двумерная таблица
Есть запросы, которые возвращают несколько колонок. Хороший пример это запрос из прошлого упражнения по агрегированию. Будучи подзапросом, он просто вернет еще одну таблицу, по которой можно делать новые запросы. Продолжая предыдущее упражнение, если мы хотим узнать количество книг, написанных автором “Robin Sharma”, то один из возможных способов - использовать подзапросы:
SELECT * FROM (SELECT author, sum(stock) FROM books GROUP BY author) AS results WHERE author="Robin Sharma";
Результат:
Можно записать как: ["Robin Sharma", "Dan Brown"]
2. Теперь используем этот результат в новом запросе:
SELECT title, bookid FROM books WHERE author IN (SELECT author FROM (SELECT author, sum(stock) FROM books GROUP BY author) AS results WHERE sum > 3);
Результат:
| title | bookid |
|---|---|
| The Lost Symbol | 2 |
| Who Will Cry When You Die? | 3 |
| Inferno | 4 |
Это то же самое, что:
SELECT title, bookid FROM books WHERE author IN ("Robin Sharma", "Dan Brown");
6.3 Отдельные значения
Бывают запросы, результатом которых являются всего одна строка и одна колонка. К ним можно относиться как к константным значениям, и их можно использовать везде, где используются значения, например, в операторах сравнения. Их также можно использовать в качестве двумерных таблиц или массивов, состоящих из одного элемента.
Давайте, к примеру, получим информацию о всех книгах, количество которых в библиотеке превышает среднее значение в данный момент.
Среднее количество можно получить таким образом:
select avg(stock) from books;
Что дает нам:
7. Операции записи
Большинство операций записи в базе данных довольно просты, если сравнивать с более сложными операциями чтения.
7.1 Update
Синтаксис запроса UPDATE семантически совпадает с запросом на чтение. Единственное отличие в том, что вместо выбора колонок SELECT "ом, мы задаем знаения SET "ом.
Если все книги Дэна Брауна потерялись, то нужно обнулить значение количества. Запрос для этого будет таким:
UPDATE books SET stock=0 WHERE author="Dan Brown";
WHERE делает то же самое, что раньше: выбирает строки. Вместо SELECT , который использовался при чтении, мы теперь используем SET . Однако, теперь нужно указать не только имя колонки, но и новое значение для этой колонки в выбранных строках.
7.2 Delete
Запрос DELETE это просто запрос SELECT или UPDATE без названий колонок. Серьезно. Как и в случае с SELECT и UPDATE , блок WHERE остается таким же: он выбирает строки, которые нужно удалить. Операция удаления уничтожает всю строку, так что не имеет смысла указывать отдельные колонки. Так что, если мы решим не обнулять количество книг Дэна Брауна, а вообще удалить все записи, то можно сделать такой запрос:
DELETE FROM books WHERE author="Dan Brown";
7.3 Insert
Пожалуй, единственное, что отличается от других типов запросов, это INSERT . Формат такой:
INSERT INTO x (a,b,c) VALUES (x, y, z);
Где a , b , c это названия колонок, а x , y и z это значения, которые нужно вставить в эти колонки, в том же порядке. Вот, в принципе, и все.
Взглянем на конкретный пример. Вот запрос с INSERT , который заполняет всю таблицу "books":
INSERT INTO books (bookid,title,author,published,stock) VALUES (1,"Scion of Ikshvaku","Amish Tripathi","06-22-2015",2), (2,"The Lost Symbol","Dan Brown","07-22-2010",3), (3,"Who Will Cry When You Die?","Robin Sharma","06-15-2006",4), (4,"Inferno","Dan Brown","05-05-2014",3), (5,"The Fault in our Stars","John Green","01-03-2015",3);
8. Проверка
Мы подошли к концу, предлагаю небольшой тест. Посмотрите на тот запрос в самом начале статьи. Можете разобраться в нем? Попробуйте разбить его на секции SELECT , FROM , WHERE , GROUP BY , и рассмотреть отдельные компоненты подзапросов.
Вот он в более удобном для чтения виде:
SELECT members.firstname || " " || members.lastname AS "Full Name" FROM borrowings INNER JOIN members ON members.memberid=borrowings.memberid INNER JOIN books ON books.bookid=borrowings.bookid WHERE borrowings.bookid IN (SELECT bookid FROM books WHERE stock> (SELECT avg(stock) FROM books)) GROUP BY members.firstname, members.lastname;
Этот запрос выводит список людей, которые взяли из библиотеки книгу, у которой общее количество выше среднего значения.
Результат:
| Full Name |
|---|
| Lida Tyler |
Надеюсь, вам удалось разобраться без проблем. Но если нет, то буду рад вашим комментариям и отзывам, чтобы я мог улучшить этот пост.
sql часто называют языком эсперанто для систем управления базами данных (СУБД). Действительно, в мире нет другого языка для работы с базами данных (БД), который бы настолько широко использовался в программах. Первый стандарт sol появился в 1986 г. и к настоящему времени завоевал всеобщее признание. Его можно использовать даже при работе с нереляционными СУБД. В отличие от других программных средств, таких, как языки Си и Кобол, являющихся прерогативой программистов-профессионалов, sql применяется специалистами из самых разных областей. Программисты, администраторы СУБД, бизнес-аналитики — все они с успехом обрабатывают данные с помощью sql. Знание этого языка полезно всем, кому приходится иметь дело с БД.
В этой статье мы рассмотрим основные понятия sql. Расскажем его предысторию (и развеем попутно несколько мифов). Вы познакомитесь с реляционной моделью и сможете приобрести первые навыки работы с sql, что поможет в дальнейшем освоении языка.
Трудно ли изучить sql? Это зависит от того, насколько глубоко вы собираетесь вникать в суть. Для того чтобы стать профессионалом, придется изучить очень многое. Язык sql появился в 1974 г. как предмет небольшой исследовательской работы, состоявшей из 23 страниц, и с тех пор прошел долгий путь развития. Текст действующего ныне стандарта — официального документа "the international standard database language sql" (обычно называемого sql-92) — содержит свыше шести сотен страниц, однако в нем ничего не говорится о конкретных особенностях версий sol, реализованных в СУБД фирм microsoft, oracle, sybase и др. Язык настолько развит и разнообразен, что лишь простое перечисление его возможностей потребует нескольких журнальных статей, а если собрать все, что написано на тему sol, то получится многотомная библиотека.
Однако для обычного пользователя совсем не обязательно знать sql целиком и полностью. Как туристу, оказавшемуся в стране, где говорят на непонятном языке, достаточно выучить лишь несколько употребительных выражений и правил грамматики, так и в sql — зная немногое, можно получать множество полезных результатов. В этой статье мы рассмотрим основные команды sql, правила задания критериев для отбора данных и покажем, как получать результаты. В итоге вы сможете самостоятельно создавать таблицы и вводить в них информацию, составлять запросы и работать с отчетами. Эти знания могут стать базой для дальнейшего самостоятельного освоения sql.
Что такое sql?
sql — это специализированный непроцедурный язык, позволяющий описывать данные, осуществлять выборку и обработку информации из реляционных СУБД. Специализированность означает, что sol предназначен лишь для работы с БД; нельзя создать полноценную прикладную систему только средствами этого языка — для этого потребуется использовать другие языки, в которые можно встраивать sql-команды. Поэтому sql еще называют вспомогательным языковым средством для обработки данных. Вспомогательный язык используется только в комплексе с другими языками.
В прикладном языке общего назначения обычно имеются средства для создания процедур, а в sql их нет. С его помощью нельзя указать, каким образом должна выполняться некоторая задача, а можно лишь определить, в чем именно она заключается. Другими словами, при работе с sql нас интересуют результаты, а не процедуры для их получения.
Наиболее существенным свойством sql является возможность доступа к реляционным БД. Многие даже считают, что выражения "БД, обрабатываемая средствами sql" и "реляционная БД" — синонимы. Однако скоро вы убедитесь, что между ними имеется разница. В стандарте sql-92 даже нет термина отношение (relation).
Что такое реляционная СУБД?
Если не вдаваться в подробности, то реляционная СУБД — это система, основанная на реляционной модели управления данными.
Понятие реляционной модели было впервые предложено в работе д-ра Е. Ф. Кодда, опубликованной в 1970 г. В ней был описан математический аппарат для структуризации данных и управления ими, а также предложена абстрактная модель для представления любой реальной информации. До этого при использовании БД требовалось учитывать конкретные особенности хранения в ней информации. Если внутренняя структура БД изменялась (например, с целью повышения быстродействия), приходилось перерабатывать прикладные программы, даже если на логическом уровне никаких изменений не происходило. Реляционная модель позволила отделить частные особенности хранения данных от уровня прикладной программы. В самом деле, модель никак не описывает способы хранения информации и доступа к ней. Учитывается лишь то, как эта информация воспринимается пользователем. Благодаря появлению реляционной модели качественно изменился подход к управлению данными: из искусства оно превратилось в науку, что привело к революционному развитию отрасли.
Основные понятия реляционной модели
Согласно реляционной модели, отношение (relation) — это некоторая таблица с данными. Отношение может иметь один или несколько атрибутов (признаков), соответствующих столбцам этой таблицы, и некоторое множество (возможно, пустое) данных, представляющих собой наборы этих атрибутов (их называют n-арными кортежами, или записями) и соответствующих строкам таблицы.
Для любого кортежа значения атрибутов должны принадлежать так называемым доменам. Фактически доменом является некоторый набор данных, который задает множество всех допустимых значений.
Давайте рассмотрим пример. Пусть имеется домен ДниНедели, содержащий значения от Понедельник до Воскресенье. Если отношение имеет атрибут ДеньНедели, соответствующий этому домену, то в любом кортеже отношения в столбце ДеньНедели должно присутствовать одно из перечисленных значений. Появление значений Январь или Кошка не допускается.
Обратите внимание: атрибут обязательно должен иметь одно из допустимых значений. Задание сразу нескольких значений запрещено. Таким образом, помимо требования принадлежности значений атрибута некоторому домену, должно соблюдаться условие его атомарности. Это означает, что для этих значений недопустима декомпозиция, т. е. нельзя разбить их на более мелкие части, не потеряв основного смысла. Например, если бы значение атрибута одновременно содержало Понедельник и Вторник, то можно было бы выделить две части, сохранив первоначальный смысл — ДеньНедели; следовательно, это значение атрибута не является атомарным. Однако если попробовать разбить значение "Понедельник" на части, то получится набор из отдельных букв — от "П" до "К"; исходный смысл утерян, поэтому значение "Понедельник" является атомарным.
Отношения обладают и другими свойствами. Наиболее значимое из них — математическое свойство замкнутости операций. Это означает, что в результате выполнения любой операции над отношением должно появляться новое отношение. Это свойство позволяет при выполнении математических операций над отношениями получать предсказуемые результаты. Кроме того, появляется возможность представлять операции в виде абстрактных выражений с разными уровнями вложенности.
В своей исходной работе д-р Кодд определил набор из восьми операторов, получивший название реляционной алгебры. Четыре оператора — объединение, логическое умножение, разность и Декартово произведение — были перенесены из традиционной теории множеств; остальные операторы были созданы специально для обработки отношений. В последующих работах д-ра Кодда, Криса Дейта и других исследователей были предложены дополнительные операторы. Далее в этой статье будут рассмотрены три реляционных оператора — продукция (project), ограничения (select, или restrict) и слияние (join).
sql и реляционная модель
Теперь, когда вы познакомились с реляционной моделью, давайте забудем о ней. Конечно, не навсегда, а лишь для того, чтобы объяснить следующее: хотя именно предложенная д-ром Коддом реляционная модель была использована при разработке sql, между ними нет полного или буквального соответствия (это одна из причин, почему в стандарте sql-92 отсутствует термин отношение). Например, понятия таблица sql и отношение не являются равнозначными, потому что в таблицах может быть сразу несколько одинаковых строк, тогда как в отношениях появление идентичных кортежей не разрешено. К тому же в sql не предусмотрено использование реляционных доменов, хотя в некоторой степени их роль играют типы данных (некоторые влиятельные сторонники реляционной модели предпринимают сейчас попытку добиться включения в будущий стандарт sql реляционных доменов).
К сожалению, несоответствие между sql и реляционной моделью породило множество недоразумений и споров за прошедшие годы. Но так как основная тема статьи — изучение sql, а не реляционной модели, эти проблемы здесь не рассматриваются. Просто следует запомнить, что между терминами, применяемыми в sql и в реляционной модели, имеются различия. Далее в статье будут использоваться только термины, принятые в sql. Вместо отношений, атрибутов и кортежей будем применять их sql-аналоги: таблицы, столбцы и строки.
Статический и динамический sql
Возможно, вам уже знакомы такие термины, как статический и динамический sql. sql-запрос является статическим, если он компилируется и оптимизируется на стадии, предшествующей выполнению программы. Мы уже упоминали одну из форм статического sql, когда говорили о встраивании sql-команд в программы на Си или Коболе (для таких выражений существует еще другое название — встроенный sql). Как вы, наверное, догадываетесь, динамический sql-запрос компилируется и оптимизируется в ходе исполнения программы. Как правило, обычные пользователи применяют именно динамический sql, позволяющий создавать запросы в соответствии с сиюминутными нуждами. Один из вариантов изпользования динамических sql-запросов — их интерактивный или непосредственный вызов (существует даже специальный термин — directsql), когда отправляемые на обработку запросы вводятся в интерактивном режиме с терминала. Между статическим и динамическим sql имеются определенные различия в синтаксисе применяемых конструкций и особенностях исполнения, однако эти вопросы выходят за рамки статьи. Отметим лишь, что для ясности понимания примеры даются в форме direct sql-запросов, поскольку это позволяет научиться использовать sql не только программистам, но и большинству конечных пользователей.
Как изучать sql
Теперь вы готовы к написанию своих первых sql-запросов. Если у вас имеется доступ к БД через sql и вы захотите воспользоваться нашими примерами на практике, то учтите следующее: вы должны входить в систему как пользователь с неограниченными полномочиями и вам потребуются программные средства интерактивной обработки sql-запросов (если речь идет о сетевой БД, следует переговорить с администратором БД о предоставлении вам соответствующих прав). Если доступа к БД через sql нет — не огорчайтесь: все примеры очень простые и в них можно разобраться "всухую", без выхода на машину.
Для того чтобы выполнить какие-либо действия в sql, следует выполнить выражение на языке sql. Встречается несколько типов выражений, однако среди них можно выделить три основные группы: ddl-команды (data definition language — язык описания данных), dml-команды (data manipulation language — язык манипуляций с данными) и средства контроля за данными. Таким образом, в sql в каком-то смысле объединены три различных языка.
Команды языка описания данных
Начнем с одной из основных ddl-команд — create table (Создать таблицу). В sql бывают таблицы нескольких типов, основными являются два типа: базовые (base) и выборочные (views). Базовыми являются таблицы, относящиеся к реально существующим данным; выборочные — это "виртуальные" таблицы, которые создаются на основе информации, получаемой из базовых таблиц; но для пользователей формы выглядят как обычные таблицы. Команда create table предназначена для создания базовых таблиц.
В команде create table следует задать название таблицы, указать список столбцов и типы содержащихся в них данных. В качестве параметров могут присутствовать также другие необязательные элементы, однако сначала давайте рассмотрим только основные параметры. Покажем простейшую синтаксическую форму для этой команды:
create table ИмяТаблицы (Столбец ТипДанных) ;
create и table — это ключевые слова sql; ИмяТаблицы, Столбец и ТипДанных — это формальные параметры, вместо которых пользователь каждый раз вводит фактические значения. Параметры Столбец и ТипДанных заключены в круглые скобки. В sql круглые скобки обычно используются для группировки отдельных элементов. В данном случае они позволяют объединить определения для столбца. Стоящий в конце знак "точка с запятой" является разделителем команд. Он должен завершать любое выражение на языке sql.
Рассмотрим пример. Пусть нужно создать таблицу для хранения данных обо всех встречах (appointments). Для этого в sql следует ввести команду:
create table appointments (appointment_date date) ;
После выполнения этой команды будет создана таблица с именем appointments, где имеется один столбец appointment_date, в котором могут записываться данные типа date. Поскольку на текущий момент данные еще не вводились, количество строк в таблице равно нулю (с помощью команды create table только дается определение таблицы; реальные значения вводятся командой insert, которая рассматривается далее).
Параметры appointments и appointment_date называются идентификаторами, поскольку они задают имена для конкретных объектов БД, в данном случае — имена для таблицы и столбца соответственно. В sql встречаются идентификаторы двух типов: обычные (regular) и выделенные (delimited). Выделенные идентификаторы заключаются в двойные кавычки, и в них учитывается регистр используемых символов. Обычные идентификаторы не выделяются никакими ограниченными символами, в их написании регистр не учитывается. В этой статье применяются только обычные идентификаторы.
Символы, используемые для построения идентификаторов, должны удовлетворять определенным правилам. В обычных идентификаторах могут использоваться только буквы (не обязательно латинские, но и других алфавитов), цифры и символ подчеркивания. Идентификатор не должен содержать знаков пунктуации, пробелов или специальных символов (#, @, % или!); кроме того, он не может начинаться с цифры или знака подчеркивания. Для идентификаторов можно использовать отдельные ключевые слова sql, но делать это не рекомендуется. Идентификатор предназначен для обозначения некоторого объекта, поэтому у него должно быть уникальное (в рамках определенного контекста) имя: нельзя создать таблицу с именем, которое уже встречается в БД; в одной таблице нельзя иметь столбцы с одинаковыми именами. Кстати, имейте в виду, что appointments и appointments — это одинаковые имена для sql. Одним лишь изменением регистра букв создать новый идентификатор нельзя.
Хотя таблица может иметь всего один столбец, на практике обычно требуются таблицы с несколькими столбцами. Команда для создания такой таблицы в общем виде выглядит так:
create table ИмяТаблицы (Столбец ТипДанных [ { , Столбец ТипДанных } ]) ;
Квадратные скобки использованы для обозначения необязательных элементов, фигурные содержат элементы, которые могут представлять собой перечень однопутных конструкций (при вводе реальной sql-команды ни те ни другие скобки не ставятся). Такой синтаксис позволяет задать любое число столбцов. Обратите внимание, что перед вторым элементом стоит запятая. Если в списке имеется несколько параметров, то они отделяются друг от друга запятыми.
create table appointments2 (appointment_date date , appointment_time time , description varchar (256)) ;
Данная команда создает таблицу appointments2 (новая таблица должна иметь иное имя, так как таблица appointments уже присутствует в БД). Как и в первой таблице, в ней имеется столбец appointment_date для записи даты встреч; кроме того, появился столбец appointment_time для записи времени этих встреч. Параметр description (описание) является текстовой строкой, где может содержаться до 256 символов. Для этого параметра указан тип varchar (сокращение от character varying), поскольку заранее не известно, сколько места потребуется для записи, но ясно, что описание займет не более 256 символов. При описании параметро в типа символьная строка (и некоторых других типов) указывается длина параметра. Ее значение задается в круглых скобках справа от названия типа.
Возможно, вы обратили внимание, что в двух рассмотренных примерах запись команды оформлена по-разному. Если в первом случае команда полностью размещена в одной строке, то во втором после первой открытой круглой скобки запись продолжена с новой строки, и определение каждого следующего столбца начинается с новой строки. В sql нет специальных требований к оформлению записи. Разбиение записи на строки делает ее чтение удобнее. Язык sql позволяет при написании команд не только разбивать команду по строкам, но и вставлять отступы в начале строк и пробелы между элементами записи.
Теперь, когда вы знаете основные правила, давайте рассмотрим более сложный пример создания таблицы с несколькими столбцами. В начале статьи была показана таблица employees (Сотрудники). В ней содержатся следующие столбцы: фамилия, имя, дата приема на работу, подразделение, категория и зарплата за год. Для определения этой таблицы используется следующая команда sql:
create table employees (last_name character (13) not null, first_name character (10) not null, hire_date date , branch_office character (15) , grade_level smallint , salary decimal (9 , 2)) ;
В команде встречаются несколько новых элементов. Прежде всего, это выражение not null, стоящее в конце определения столбцов last_name и first_name. С помощью подобных конструкций задаются требования, подлежащие обязательному соблюдению. В данном случае указано, что поля last_name и first_name должны обязательно заполняться при вводе; оставлять эти столбцы пустыми нельзя (это вполне логично: как можно идентифицировать сотрудника, не зная его имени?).
Кроме того, в примере присутствуют три новых типа данных: character, smallint и decimal. До сих пор мы почти не говорили о типах. Хотя в sql нет реляционных доменов, однако имеется набор основных типов данных. Эта информация используется при выделении памяти и сравнении величин; в определенной степени сужает список возможных значений при вводе, однако контроль типов в sql менее строгий, чем в других языках.
Все имеющиеся в sql типы данных можно разбить на шесть групп: символьные строки, точные числовые значения, приближенные числовые значения, битовые строки, датовремя и интервалы. Мы перечислили все разновидности, однако в этой статье подробно будут рассматриваться лишь отдельные из них (битовые строки, например, не представляют особого интереса для обычных пользователей).
Кстати, если вы подумали, что датовремя — это опечатка, то ошиблись. К данной группе (datetime) относится большинство используемых в sql типов данных, связанных со временем (такие параметры, как временные интервалы, выделены в отдельную группу). В предыдущем примере уже встречались два типа данных из группы датовремя — date и time.
Следующий тип данных, с которым вы уже знакомы, — character varying (или просто varchar); он относится к группе символьных строк. Если varchar служит для хранения строк переменной длины, то встретившийся в третьем примере тип char предназначен для записи строк, имеющих фиксированное число символов. Например, в столбце last_name будут записываться строки из 13 символов вне зависимости от реально вводимых фамилий, будь то poe или penworth-chickering (в случае с poe оставшиеся 10 символов заполнятся пробелами).
С точки зрения пользователя, varchar и char имеют одинаковый смысл. Зачем нужно было вводить два типа? Дело в том, что на практике обычно приходится искать компромисс между быстродействием и экономией пространства на диске. Как правило, применение строк с фиксированной длиной дает некоторый выигрыш в скорости доступа, однако при слишком большой длине строк пространство на диске расходуется неэкономно. Если в appointments2 для каждой строки комментария резервировать по 256 символов, то это может оказаться нерационально; чаще всего строки будут значительно короче. С другой стороны, фамилии также имеют разную длину, но для них, как правило, требуется около 13 символов; в этом случае потери будут минимальными. Существует хорошее правило: если известно, что длина строки меняется незначительно либо она сравнительно невелика, то используйте char; в остальных случаях — varchar.
Следующие два новых типа данных — smallint и decimal — относятся к группе точных числовых значений. smallint — это сокращенное название от small integer (малое целое). В sql также предусмотрен тип данных integer. Наличие двух схожих типов и в этом случае объясняется соображением экономии пространства. В нашем примере значения параметра grade_level могут быть представлены с помощью двузначного числа, поэтому использован тип smallint; однако на практике не всегда известно, какие максимальные значения могут быть у параметров. Если такой информации нет, то применяйте integer. Реальный объем, выделяемый для хранения параметров типа smallint и integer, и соответствующий диапазон значений для этих параметров индивидуальны для каждой платформы.
Тип данных decimal, обычно используемый для учета финансовых показателей, позволяет задать шаблон с требуемым числом десятичных знаков. Поскольку этот тип служит для точной числовой записи, он гарантирует точность при выполнении математических операций над десятичными данными. Если для десятичных значений использовать типы данных из группы приближенной числовой записи, например float (floating point number — число с плавающей точкой), это приведет к погрешностям округления, поэтому для финансовых расчетов этот вариант не подходит. Для определения параметров типа decimal используется следующая форма записи:
где p — это число десятичных знаков, d — количество разрядов после запятой. Вместо p следует записывать общее число значащих цифр в используемых значениях, а вместо d — количество цифр после запятой.
Во врезке "Создание таблицы" показан полный вариант обобщенной записи команды create table. В нем присутствуют новые элементы и показан формат для всех рассмотренных типов данных (В принципе встречаются и другие типы данных, но пока мы их не рассматриваем).
На первых порах может показаться, что синтаксис sql-команд слишком сложен. Но вы легко в нем разберетесь, если внимательно изучили приведенные выше примеры. На схеме появился дополнительный элемент — вертикальная черта; он служит для разграничения альтернативных конструкций. Другими словами, при определении каждого столбца нужно выбрать подходящий тип данных (как вы помните, в квадратные скобки заключаются необязательные параметры, а в фигурные скобки — конструкции, которые могут повторяться многократно; в реальных sql-командах эти специальные символы не пишутся). В первой части схемы приведены полные названия для типов данных, во второй — их сокращенные названия; на практике можно использовать любые из них.
Первая часть статьи завершена. Вторая будет посвящена изучению dml-команд insert, select, update и delete. Также будут рассмотрены условия выборки данных, операторы сравнения и логические операторы, использование null-значений и троичная логика.
Создание таблицы. Синтаксис команды create table: в квадратных скобках указаны необязательные параметры, в фигурных — повторяющиеся конструкции.
create table table (column character (length) [ constraint ] | character varying (length) [ constraint ] | date [ constraint ] | time [ constraint ] | integer [ constraint ] | smallint [ constraint ] | decimal (precision, decimal places) [ constraint ] | float (precision) [ constraint ] [{ , column char (length) [ constraint ] | varchar (length) [ constraint ] | date [ constraint ] | time [ constraint ] | int [ constraint ] | smallint [ constraint ] | dec (precision, decimal places) [ constraint ] | float (precision) [ constraint ] }]) ;
Секрет названия sql
В начале 1970-х гг. в ibm приступили к практическому воплощению модели реляционных БД, предложенной д-ром Коддом. Дональд Чамберлин и группа других сотрудников подразделения перспективных исследований создали прототип языка, получивший название structured english query language (язык структурированных англоязычных запросов), или просто sequel. В дальнейшем он был расширен и подвергнут доработке. Новый вариант, предложенный ibm, получил название sequel/2. Его использовали как программный интерфейс (api) для проектирования первой реляционной системы БД фирмы ibm — system/r. Из соображений, связанных с правовыми нюансами, в ibm решили изменить название: вместо sequel/2 использовать sql (structured query language). Эту аббревиатуру часто произносят как "си-ку-эл".
Всем привет! Сегодня я максимально просто, специально для начинающих, попытаюсь рассказать Вам о том, что такое SQL , и для чего он нужен. Из данного материала Вы также узнаете, что такое база данных и система управления базами данных, а также что такое диалект языка SQL, ведь вся статья будет построена на том, чтобы плавно подвести Вас к пониманию того, что же такое SQL.
Я думаю, Вы уже представляете себе, что SQL — это некий язык, связанный с какими-то там базами данных, однако для того, чтобы лучше понимать, что же такое SQL, необходимо понять, для чего нужен SQL, для чего нужен этот язык, т.е. его назначение.
Поэтому сначала я дам Вам немного вводной информации, из которой будет ясно назначение языка SQL, и для чего он вообще нужен.
Что такое база данных
И начну я с того, что под базой данных обычно принято понимать любой набор информации, которая хранится определенным образом, и ей можно воспользоваться. Но если говорить о каких-то автоматизированных базах данных, то здесь, конечно же, речь идет о так называемых реляционных базах данных.
Реляционная база данных – это упорядоченная информация, связанная между собой определёнными отношениями. Представлена она в виде таблиц, в которых и лежит вся эта информация. И это очень важно, так как теперь Вы должны представлять себе современную базу данных просто в виде таблиц (если говорить в контексте SQL ), т.е. в общем смысле база данных – это набор таблиц. Безусловно, это сильно упрощенное определение, но оно дает некое практическое понимание базы данных.
Что такое SQL
За счет того, что информация в базе данных упорядочена, разделена на определённые сущности и представлена в виде таблиц, к ней легко обратиться и найти нужную нам информацию.
И тут возникает главный вопрос: а как к ней обратиться и получить необходимую нам информацию?
Для этого должен быть специальный инструмент, и здесь к нам на помощь как раз и приходит SQL, который является тем инструментом, с помощью которого происходит манипулирование данными (создание, извлечение, удаление и т.д. ) в базе данных.
SQL (Structured Query Language ) — язык структурированных запросов, с помощью него пишутся специальные запросы (так называемые SQL инструкции ) к базе данных с целью получения данных из базы данных или для манипулирования этими данными.
Также обязательно стоит отметить и то, что база данных, и в частности реляционная модель, основана на теории множеств, которая подразумевает объединение разных объектов в одно целое, под одним целым в базе данных как раз и имеется в виду таблица. Это важно, так как язык SQL работает именно со множеством, с набором данных, т.е. с таблицами.
Полезные материалы по теме:
- Создание базы данных в Microsoft SQL Server – инструкция для новичков ;
- Добавление данных в таблицы в Microsoft SQL Server – инструкция INSERT INTO .
Что такое СУБД
У Вас может возникнуть вопрос, если база данных это некая информация, которая хранится в таблицах, то как она выглядит физически? Как на нее посмотреть в целом?
Если очень коротко, то это просто файл, созданный в специальном формате, именно так и выглядит база данных (в большинстве случаев БД включает несколько файлов, но сейчас на этом уровне это не так важно ).
Идем дальше, если база данных это файл в специальном формате, то как его создать или открыть? И тут возникает сложность, ведь просто так, без каких-либо инструментов создать такой файл, т.е. реляционную базу данных, нельзя, для этого нужен специальный инструмент, который мог бы создавать и управлять базой данных, иными словами, работать с этими файлами.
Таким инструментом как раз и выступает СУБД – это система управления базами данных , сокращенно СУБД.
Какие СУБД бывают
На самом деле, существует достаточно много различных СУБД, некоторые из них платные и стоят немалых денег, если говорить о полнофункциональных версиях, но даже у самых, так скажем, «крутых» есть бесплатные редакции, которые, кстати, отлично подходят для обучения.
Среди всех по своим возможностям и популярности можно выделить следующие системы:
- Microsoft SQL Server – это система управления базами данных от компании Microsoft. Она очень популярна в корпоративном секторе, особенно в крупных компаниях. И это не просто СУБД – это целый комплекс приложений, позволяющий хранить и модифицировать данные, анализировать их, осуществлять безопасность этих данных и многое другое;
- Oracle Database – это система управления базами данных от компании Oracle. Это также очень популярная СУБД, и также среди крупных компаний. По своим возможностям и функциональности Oracle Database и Microsoft SQL Server сопоставимы, поэтому являются серьезными конкурентами друг другу, и стоимость их полнофункциональных версий очень высока;
- MySQL – это система управления базами данных также от компании Oracle, но только она распространяется бесплатно. MySQL получила очень широкую популярность в интернет сегменте, т.е. именно на MySQL работают чуть ли не все сайты в интернете, иными словами, большинство сайтов в интернете используют эту СУБД как средство хранения данных;
- PostgreSQL – эта система управления базами данных также является бесплатной, и она очень популярна и функциональна.
Полезные материалы по теме:
- Установка Microsoft SQL Server 2016 Express – пример установки бесплатной редакции Microsoft SQL Server на Windows;
- Установка Microsoft SQL Server 2017 Express на Ubuntu Server – пример установки бесплатной редакции Microsoft SQL Server на Linux;
- Установка PostgreSQL 11 на Windows – пример установки PostgreSQL на Windows;
- Установка MySQL на Windows – пример установки MySQL на Windows;
- Установка и настройка MySQL на Linux Mint – пример установки MySQL на Linux;
- Установка Oracle Database Express Edition 11g – пример установки бесплатной редакции Oracle на Windows (статья писалась давно, но все равно будет полезной ).
Диалекты языка SQL (расширения SQL)
Язык SQL – это стандарт, он реализован во всех реляционных базах данных, но у каждой СУБД есть расширение этого стандарта, есть собственный язык работы с данными, его обычно называют диалектом SQL, который, конечно же, основан на SQL, но предоставляет больше возможностей для полноценного программирования, кроме того, такой внутренний язык дает возможность получать системную информацию и упрощать SQL запросы.
Вот некоторые диалекты языка SQL:
- Transact-SQL (сокращенно T-SQL) – используется в Microsoft SQL Server;
- PL/SQL (Procedural Language / Structured Query Language) – используется в Oracle Database;
- PL/pgSQL (Procedural Language/PostGres Structured Query Language) – используется в PostgreSQL.
Таким образом, от СУБД зависит, на каком расширении Вы будете писать SQL инструкции. Если говорить о простых SQL запросах, например,
SELECT ProductId, ProductName FROM Goods
то, безусловно, во всех СУБД такие запросы работать будут, ведь SQL — это стандарт.
Примечание! Это простой SQL запрос на выборку данных из одной таблицы, выводятся два столбца.
Однако если Вы собираетесь программировать, использовать все внутренние возможности СУБД (разрабатывать процедуры, использовать встроенные функции, получать системную информацию и т.д. ), то Вам необходимо изучать конкретный диалект SQL и практиковаться соответственно в той СУБД, в которой используется этот диалект. Это важно, ведь синтаксис многих конструкций различается так же, как различаются возможности и многое другое. И если, допустим, Вы запустите SQL инструкцию, в которой использованы возможности определенного расширения SQL, на другой СУБД, то такая инструкция, конечно же, не выполнится.
Например, лично я специализируюсь на языке T-SQL, и соответственно, работаю с Microsoft SQL Server, вот уже более 8 лет!
Хотя, конечно же, с другими СУБД я также работал, одно время я сопровождал два приложения, одно из которых работало с PostgreSQL, ну а второе, наверное, уже понятно, с Microsoft SQL Server.
С MySQL я работал, как, наверное, и многие, в рамках сопровождения сайтов и сервисов. Ну а с Oracle Database мне приходилось работать в рамках других проектов.
Весь свой накопленный опыт в части языка T-SQL я сгруппировал в одном месте и оформил в виде книг, поэтому, если у Вас есть желание изучить язык Transact-SQL (T-SQL), рекомендую почитать мои книги:
- Путь программиста T-SQL – самоучитель по языку Transact-SQL для начинающих. В ней я подробно рассказываю обо всех конструкциях языка и последовательно перехожу от простого к сложному. Подходит для комплексного изучения языка T-SQL;
- Стиль программирования на T-SQL – основы правильного написания кода. Книга, направленная на повышение качества T-SQL кода (для тех, кто уже знаком с языком T-SQL, т.е. знает хотя бы основы ).
Надеюсь, теперь Вы понимаете, что такое SQL, и для чего он нужен, в следующих материалах я расскажу, как создавать SQL запросы, расскажу какие инструменты для этого необходимо использовать и для каких СУБД, так как у каждой СУБД есть свои инструменты, поэтому следите за выходом новых статей в моих группах в социальных сетях.